

พี่จีนทำโลกตะลึงอีกแล้ว ด้วยการเปิดตัว DeepSeek ปัญญาประดิษฐ์หรือ AI ที่มีประสิทธิภาพสูงเทียบเคียงกับเจ้าตลาดอย่าง OpenAI ChatGPT แถมยังใช้ต้นทุนในการพัฒนาที่ต่ำกว่าหลายเท่า เอาล่ะเดี๋ยวเราไปทำความรู้จักกันสักหน่อยว่ามันมีความเป็นมาอย่างไรครับ
กว่าจะมาเป็น DeepSeek

DeepSeek เป็นบริษัทปัญญาประดิษฐ์จากจีนที่ก่อตั้งขึ้นในเดือนกรกฎาคม 2023 โดย เหลียง เวินเฟิง (Liang Wenfeng) ศิษย์เก่ามหาวิทยาลัยเจ้อเจียง บริษัทนี้เติบโตภายใต้การสนับสนุนของกองทุน High-Flyer ที่เหลียงก่อตั้งมาตั้งแต่ปี 2015 ซึ่งมีบทบาทสำคัญในการสะสมทรัพยากรประมวลผลขั้นสูงสำหรับพัฒนา AI ด้วยความที่กองทุนก็เป็นของเหลียงเอง แบบนี้ก็พัฒนากันได้สบาย ๆ ไม่ต้องขึ้นตรงกับใคร
เหลียงเป็นคนที่ค่อนข้างมองการณ์ไกล เขาต้องการผลักดันให้เกิดการพัฒนาด้าน AI ภายในประเทศจีน แต่ด้วยความที่จีนกำลังจะโดนสหรัฐฯ แบนการเข้าถึงเทคโนโลยีระดับสูงในการพัฒนา AI โดยเฉพาะการ์ดจอเทรน AI ทำให้เหลียงนำเงินทุนไปจัดซื้อการ์ดจอ NVIDIA A100 จำนวนมาก ก่อนที่สหรัฐฯ จะออกข้อห้ามส่งออกชิปเหล่านี้ไปจีนในปี 2022
สิ่งนี้นี่แหละที่เป็นจุดเริ่มต้นให้ DeepSeek ต้องเร่งพัฒนาตนเองให้มีประสิทธิภาพมากยิ่งขึ้น
ข้อจำกัดด้านฮาร์ดแวร์ คือจุดแข็งของการพัฒนา
เมื่อสหรัฐฯ เริ่มแบนการส่งออกการ์ดจอตัวท็อป ทั้ง A100 และ H100 แถมการ์ดจอที่จัดซื้อมาในตอนแรกก็ยังมีไม่มากพอที่จะรวมพลังในการเทรนโมเดลได้ เหลียงและ DeepSeek จึงจัดซื้อการ์ดจอ NVIDIA H800 มาใช้เพิ่มเติม ซึ่งมันเป็นการ์ดจอ NVIDIA Hopper ที่ปรับลดความแรงลงสำหรับส่งขายให้ตลาดจีน
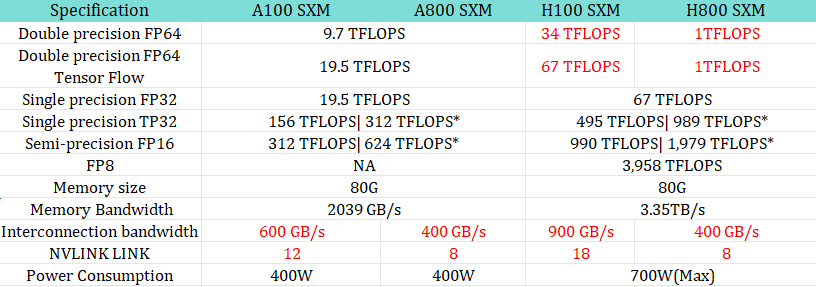
ถามว่าประสิทธิภาพมันหายไปเยอะไหม ตอบเลยว่าเยอะมากครับ ตัวอย่างเช่นการประมวลผล FP64 ใน H100 จะอยู่ที่ 34 TFLOPS ในขณะที่ H800 จะอยู่ที่ 1 FLOPS เท่านั้น ความแรงแบบนี้คือต่างกันราวฟ้ากับเหว
แต่ดูเหมือนมันจะกลายเป็นแรงผลักดันให้ DeepSeek พัฒนาอย่างต่อเนื่อง ในเมื่อการเพิ่มความแรงมันตันแล้วและจะไม่คุ้มค่า บริษัทจึงมุ่งเน้นการวิจัยเพื่อเพิ่มประสิทธิภาพการฝึกโมเดลภายใต้ทรัพยากรจำกัดแทน
กลยุทธ์การพัฒนาโมเดล AI ของ DeepSeek
ถึงจะมีข้อจำกัดในเรื่องของทรัพยากรและเทคโนโลยี แต่ทาง DeepSeek อาศัยกลยุทธ์ต่าง ๆ ในการพัฒนาโมเดล AI มีเทคนิค ดังนี้
- เทคนิค Reinforcement Learning เป็นการฝึก AI ด้วยแรงจูงใจ คล้ายคลึงกับการฝึกสัตว์เลี้ยง อาศัยการให้รางวัลและการลงโทษ หาก AI ตอบถูกก็จะได้รางวัล ถ้าตอบผิดก็จะอดได้รางวัลหรือโดนทำโทษ ทำให้ AI เกิดการเรียนรู้ให้การเฟ้นหาคำตอบที่ถูกต้องที่สุดด้วยตนเอง ซึ่งเทคนิคนี้ช่วยลดต้นทุนในการพัฒนา เพราะ AI จะคิดหาคำตอบเอง โดยไม่ผ่านการป้อนข้อมูลโดยมนุษย์ครับ
- เทคนิค Mixture-of-Experts Architecture เป็นการแบ่ง AI ให้มีความสามารถหลากหลายและเชี่ยวชาญเฉพาะด้าน สามารถเรียกส่วนนั้น ๆ มาใช้งานได้เหมาะสมตามสภาพงาน คล้าย ๆ กับถ้าถามโจทย์เลข ก็ต้องส่ง AI ที่เก่งเลขมาตอบ
- เทคนิค Multi-Head Latent Attention เป็นการทำให้ AI ทำงานหลายอย่างได้พร้อมกัน แนว ๆ เดียวกับ multi-core ในซีพียูเลยครับ
- เทคนิค Distillation เป็นการทำให้ AI สามารถถ่ายทอดข้อมูลจากโมเดลขนาดใหญ่ไปยังขนาดเล็กได้ ซึ่งจะทำให้ได้โมเดลที่มีประสิทธิภาพมากขึ้น ในขณะเดียวกันกลับใช้ทรัพยากรน้อยลง
ผลลัพธ์คือการฝึก DeepSeek โมเดล R1 ใช้ต้นทุนเพียง 5.6 ล้านดอลลาร์สหรัฐ เทียบกับต้นทุนในการพัฒนา AI ในสหรัฐฯ มีมูลค่าเริ่มต้นที่ 100 ล้านดอลลาร์สหรัฐ ที่สำคัญ DeepSeek มันเป็น Open-Source !! นี่แหละครับ เหตุการณ์นี้ทำเอาหุ้นเทคโนโลยีในสหรัฐฯ ร่วงกันระนาว
DeepSeek V3 vs. DeepSeek R1
DeepSeek R1 คือโมเดล รุ่นใหม่ล่าสุด ถูกออกแบบมาให้มีความสามารถในการคิดวิเคราะห์เชิงเหตุผล และการแก้ปัญหาที่ซับซ้อนได้อย่างเป็นขั้นเป็นตอน
จุดเด่นของ DeepSeek R1 คือการใช้สถาปัตยกรรมรูปแบบไฮบริด และวิธีการให้เหตุผลแบบ Chain of thought คือการคิดแบบเป็นขั้นตอนต่อเนื่อง ซึ่งวิธีการนี้จะคล้ายกับการทำงานของ GPT แต่ DeepSeek R1 มีความโดดเด่นในเรื่องของประสิทธิภาพและมีราคาที่ถูกกว่าเพราะใช้ต้นทุนน้อยกว่า

ต้นทุนของ DeepSeek R1 ถูกแค่ไหน? หากเทียบราคากันแล้ว API ของ DeepSeek R1 จะมีราคาเพียง 2.19 ดอลลาร์สหรัฐต่อ 1 ล้าน output tokens ในขณะที่ API ของ ChatGPT จะมีราคาสูงถึง 60 ดอลลาร์สหรัฐต่อ 1 ล้าน output token
ส่วน DeepSeek V3 อันนี้จะเปรียบเสมือนพี่ใหญ่ในตระกูล DeepSeek โดยเป็นโมเดลที่มีขนาดใหญ่มากกว่า R1 สามารถนำไปประยุกต์ใช้ในงานได้หลากหลาย โดยเฉพาะงานวิจัยและการพัฒนาเครื่องมือ AI อื่น ๆ ประสิทธิภาพนั้นย่อมดีกว่า R1 แต่ในแง่ของความใหญ่, ความเร็ว และความคล่องตัวในการใช้งานจะน้อยกว่า R1
หากเปรียบเทียบแล้ว DeepSeek V3 จะเหมือน GPT 4 ส่วน DeepSeek R1 จะเหมือน GPT 4o
ความร่วมมือกับ AMD
AMD ได้ร่วมมือกับ DeepSeek ในการผนวกโมเดล DeepSeek V3 เข้ากับการ์ดจอ AMD Instinct ที่เสริมประสิทธิภาพด้วย SGLang เพื่อพัฒนาแอปพลิเคชัน AI ยุคใหม่
อย่างที่กล่าวไว้ข้างต้นว่า DeepSeek V3 เป็นโมเดล AI แบบ Open-Source ที่ถูกพัฒนาขึ้นเพื่อนำไปใช้งานหลากหลาย ทั้งการทำวิจัย, การพัฒนาเครื่องมือ AI อีกทั้งยังมีความเข้าใจทั้งข้อความและภาพ ช่วยให้นักพัฒนาสร้างแอปพลิเคชันล้ำสมัยได้อย่างมีประสิทธิภาพ

ยิ่งไปกว่านั้น ซอฟต์แวร์ ROCm ที่รองรับ FP8 ยังช่วยเพิ่มประสิทธิภาพการทำงาน ลดปัญหาคอขวด ทำให้การเทรนโมเดล AI มีประสิทธิภาพมากขึ้น ซึ่งซอฟต์แวร์ดังกล่าวไม่ได้ถูกจำกัดการเข้าถึงโดยสหรัฐฯ ดังนั้น DeepSeek จึงสามารถนำไปใช้งานได้อย่างเต็มที่
ความร่วมมือครั้งนี้ตอกย้ำความมุ่งมั่นของ AMD ในการพัฒนา AI แบบ Open-Source และช่วยให้นักพัฒนาทั่วโลกเข้าถึงเครื่องมืออันทรงพลัง เพื่อสร้างสรรค์นวัตกรรม AI ที่ตอบโจทย์อนาคต
ขอขอบคุณข้อมูลจาก AMD, Evrimagaci, BBC
You must be logged in to post a comment.